Estadísticas¶
El sistema de estadísticas consta de dos partes. Por una parte, el servicio de estadísticas nos permite mostrar al usuario gráficas sobre objetos existentes en una capa del mapa. Por otra, el motor de cálculo nos permite generar los datos estadísticos de cobertura de forma automática.
Servicio de estadísticas¶
Este servicio nos permitirá obtener gráficos sobre objetos del mapa. Los datos a presentar en dichos gráficos pueden presentar una o más variables con datos en uno o más instantes temporales.
Para utilizar el servicio es necesario partir de la tabla con los datos a graficar. Esta tabla contendrá los datos a graficar. Requerirá:
- un campo identificador del objeto sobre el que se pide la información, por ejemplo, código de provincia
- un campo con la fecha del valor
- tantos campos como valores tenga ese objeto en esa fecha: superficie de bosque, superficie deforestada, etc.
En el siguiente ejemplo tenemos un campo identificador id y un campo fecha. Para cada objeto tenemos tres fechas en las que se mide la superficie de bosque y la superficie deforestada:
| id | sup_bosque | sup_deforestada | fecha |
|---|---|---|---|
| 1 | 400 | 100 | 2000 |
| 1 | 300 | 100 | 2005 |
| 1 | 200 | 100 | 2010 |
| 2 | 300 | 0 | 2000 |
| 2 | 350 | 100 | 2005 |
| 2 | 30 | 500 | 2010 |
Una vez se tiene la tabla con los datos hay que configurar las tablas de metadatos del servicio de estadísticas, que contiene información sobre el gráfico: título, unidades, tipo de gráfico; y permite enlazar al servicio con la tabla de datos anterior.
Instalación¶
Para que el servicio de estadísticas funcione es necesario:
Crear un esquema en la base de datos. En dicho esquema se introducirán todas las tablas usadas por el portal tanto para estadísticas como para otras funcionalidades.
Crear las tablas de metadatos
redd_stats_chartsyredd_stats_variablesque definirán el aspecto del gráfico y asociarán las capas del mapa con la tabla de datos.CREATE TABLE redd_stats_charts ( id serial PRIMARY KEY, title character varying, subtitle character varying, layer_name character varying, division_field_id character varying, division_field_name character varying, table_name_data character varying, data_table_id_field character varying, data_table_date_field character varying, data_table_date_field_format character varying, data_table_date_field_output_format character varying ) WITH ( OIDS=FALSE ); CREATE TABLE redd_stats_variables ( id serial NOT NULL PRIMARY KEY, chart_id integer, y_label character varying, units character varying, tooltipsdecimals integer, variable_name character varying, data_table_variable_field character varying, graphic_type character varying, priority integer );
Configurar el esquema en el
portal.propertiesexistente en el directorio de configuración del portal:db-schema=mi_esquema
Tras este último paso es necesario reinicializar el portal. Esto se puede realizar mediante el comando
touchaplicado al war. Este comando modifica la fecha y hora del fichero que se le pasa como parámetro, lo que fuerza a Tomcat a redesplegar el war y reinicializar la aplicación:$ touch /var/tomcat/webapps/portal.war
Configuración de la tabla de metadatos¶
Cada fila de la tabla de redd_stats_charts especificará un gráfico para los objetos de una capa del portal:
- id: identificador, rellenado automáticamente.
- title: título del gráfico
- subtitle: subtítulo del gráfico
- layer_name: Nombre en GeoServer de la capa para la que se ofrecerá el gráfico, con la forma espaciodetrabajo:nombrecapa. Por ejemplo: bosques:provincias
- division_field_id: Nombre del campo que identifica los objetos en la capa anterior. Es posible utilizar un campo que no es único si se desea tener el mismo gráfico para más de un objeto.
- division_field_name: Nombre del campo con el nombre del objeto en la capa anterior. Se incluirá en el título del gráfico.
- table_name_data: Nombre de la tabla con los datos.
- data_table_id_field: Nombre del campo identificador en la tabla de datos
table_name_data. - data_table_date_field: Nombre del campo fecha en la tabla de datos
table_name_data. - data_table_date_field_format: Formato del campo fecha si no es de tipo
datesegún la función to_date de PostgreSQL . NULL si el campo fecha es de tipodate. - data_table_date_field_output_format: Formato de las fechas en el eje X de la gráfica según la función to_date de PostgreSQL . Si se deja a NULL se tomará DD-MM-YYYY (día-mes-año).
Una vez el registro con el gráfico ha sido creado es necesario especificar cómo se presentan los datos en el gráfico en la tabla redd_stats_variables:
- id: identificador, rellenado automáticamente.
- chart_id: identificador del gráfico al que pertenece esta variable. Deberá tener valor del campo
iddel gráfico. - y_label: Magnitud medida, por ejemplo “Superficie”
- units: unidades en las que se mide la magnitud, por ejemplo “Hectáreas”
- tooltipsdecimals: Número de decimales que se presentarán cuando el usuario interactúa con la gráfica
- variable_name: Nombre de la variable que aparecerá en el gráfico, por ejemplo “bosque cultivado”.
- data_table_variable_field: Nombre del campo de la tabla de datos que contiene los valores de la variable anterior.
- graphic_type: Tipo de gráfico. Puede ser cualquier valor aceptado por la librería highcharts
- priority: Prioridad del eje. Para poder definir qué datos se presentan antes (p.ej.: líneas delante de gráfico de barras).
Caso práctico¶
En este ejemplo vamos a suponer que tenemos:
- Una tabla provincias con un campo
id_provinciacon tres provincias con identificador 1, 2 y 3. - Una capa en GeoServer, publicando la tabla anterior con el nombre
provinciasen el espacio de trabajobosques, es decir, con nombrebosques:provincias. - La tabla convenientemente publicada en el portal, de manera es es posible mostrar el diálogo de información al pinchar en una de las provincias.
Es posible descargar los datos de ejemplo aquí, para su carga en PostGIS y la realización del caso práctico con ellos.
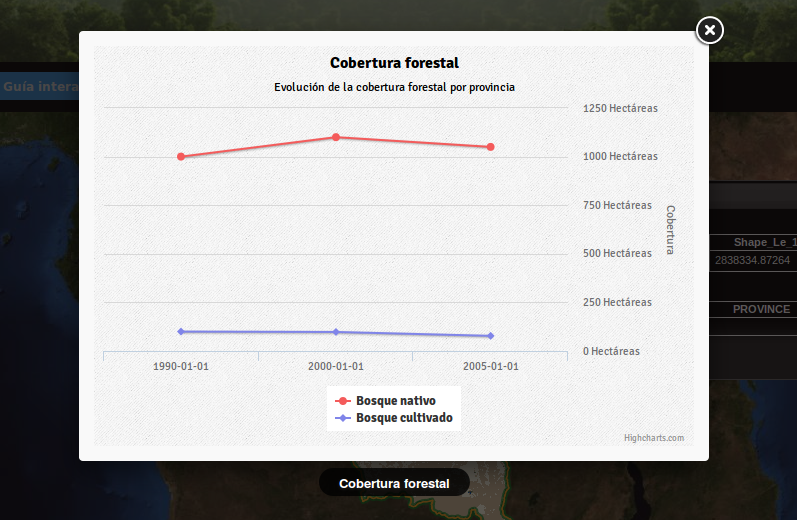
Queremos publicar los siguientes datos de cobertura forestal:
| Provincia 1 | 1990 | 2000 | 2005 |
|---|---|---|---|
| bosque nativo | 100 | 98 | 78 |
| bosque cultivado | 1000 | 1100 | 1050 |
| Provincia 2 | 1990 | 2000 | 2005 |
|---|---|---|---|
| bosque nativo | 590 | ND | 208 |
| bosque cultivado | 0 | 0 | 50 |
| Provincia 3 | 1990 | 2000 | 2005 |
|---|---|---|---|
| bosque nativo | 2000 | 2300 | 2500 |
| bosque cultivado | 0 | 100 | 50 |
Lo primero será crear la tabla de datos con cualquer nombre significativo, por ejemplo cobertura_forestal_provincias. Suponemos que creamos todo en un esquema llamado estadísticas:
CREATE TABLE estadisticas.cobertura_forestal_provincias(
id_provinc varchar,
sup_nativo varchar,
sup_cultivado varchar,
anio date
);
Una vez la tabla está creada, es necesario introducir un registro por cada dato:
INSERT INTO estadisticas.cobertura_forestal_provincias VALUES ('1', 100, 1000, '1/1/1990');
INSERT INTO estadisticas.cobertura_forestal_provincias VALUES ('1', 98, 1100, '1/1/2000');
INSERT INTO estadisticas.cobertura_forestal_provincias VALUES ('1', 78, 1050, '1/1/2005');
INSERT INTO estadisticas.cobertura_forestal_provincias VALUES ('2', 590, 0, '1/1/1990');
INSERT INTO estadisticas.cobertura_forestal_provincias VALUES ('2', null, 0, '1/1/2000');
INSERT INTO estadisticas.cobertura_forestal_provincias VALUES ('2', 208, 50, '1/1/2005');
INSERT INTO estadisticas.cobertura_forestal_provincias VALUES ('3', 2000, 0, '1/1/1990');
INSERT INTO estadisticas.cobertura_forestal_provincias VALUES ('3', 2300, 100, '1/1/2000');
INSERT INTO estadisticas.cobertura_forestal_provincias VALUES ('3', 2500, 50, '1/1/2005');
Por último crearemos el registro en la tabla de metadatos que enlaza estos datos con nuestra tabla de datos recién creada:
INSERT INTO estadisticas.redd_stats_charts VALUES (
DEFAULT, -- id generado automaticamente
'Cobertura forestal', --title
'Evolución de la cobertura forestal por provincia', --subtitle
'bosques:provincias', --capa en geoserver
'id_provinc', -- nombre del campo identificador de la capa
'estadisticas.cobertura_forestal_provincias', -- nombre de la tabla de datos
'id_provinc', -- nombre del campo id
'anio', -- nombre del campo fecha
NULL, -- campo fecha de tipo date
'YYYY-MM-DD'
);
INSERT INTO estadisticas.redd_stats_variables VALUES (
DEFAULT, -- id generado automaticamente
(select currval('estadisticas.redd_stats_charts_id_seq')), --nos da el id del último INSERT en redd_stats_charts, es decir, nuestro gráfico
'Cobertura', -- Nombre de la magnitud a medir
'Hectáreas', -- Unidades de la magnitud a medir
2, -- número de decimales a presentar
'Bosque cultivado', -- Nombre de la variable
'sup_nativo', --nombre del campo
'line', --tipo de gráfico
1 --prioridad
);
INSERT INTO estadisticas.redd_stats_variables VALUES (
DEFAULT, -- id generado automaticamente
(select currval('estadisticas.redd_stats_charts_id_seq')), --nos da el id del último INSERT en redd_stats_charts, es decir, nuestro gráfico
'Cobertura', -- Nombre de la magnitud a medir
'Hectáreas', -- Unidades de la magnitud a medir
2, -- número de decimales a presentar
'Bosque nativo', -- Nombre de la variable
'sup_cultivado', --nombre del campo
'column', --tipo de gráfico
2 --prioridad
);
Ahora, cuando el usuario pinche en una de las provincias:
- el portal buscará en la tabla
estadisticas.redd_stats_chartslos registros que afectan a la capabosques:provinciasy encontrará el registro que acabamos de introducir. - el portal ofrecerá al usuario un botón para mostrar los datos de la tabla de datos asociada
estadisticas.cobertura_forestal_provincias - el usuario pinchará en dicho botón
- el portal leerá la tabla de variables, la tabla de datos y creará el gráfico que se ofrecerá al usuario
Motor de cálculo¶
El motor de cálculo son una serie de funciones PostgreSQL/PostGIS que permiten generar la tabla de datos que se presenta en los gráficos de forma automática, tomando como entrada:
- una tabla de polígonos sobre los cuales se quieren presentar las estadísticas, típicamente divisiones administrativas, con un campo identificador
- una tabla con la cobertura forestal en la que cada registro representa un area con la misma clasificación en un instante determinado.
Y produciendo:
- la tabla con los datos de cobertura en hectáreas para cada año y objeto existente en la primera capa.
Instalación¶
El motor de cálculo puede descargarse aquí. Para su instalación es necesario ejecutarlo en un intérprete de PostGIS, por ejemplo en línea de comandos:
$ psql -U spatial_user -d spatialdata -f redd_stats_calculator.sql
Esta ejecución instalará dos funciones, redd_stats_calculo y redd_stats_run. Esta última es la que se utilizará para iniciar el motor de cálculo.
Además de las funciones, el motor espera encontrar en el mismo esquema donde se encuentra la tabla de metadatos una tabla con las fajas en proyección EPSG:4326. Esta tabla deberá tener un campo geom con la geometria y un campo srid de tipo integer con el código SRID al que pertenece cada faja. Se puede ver un ejemplo en el caso práctico más abajo.
Una vez las funciones están instaladas y la tabla redd_stats_fajas está creada, podemos empezar a utilizarlo. Para hacerlo funcionar habrá que realizar dos pasos, 1) configurar la tabla de metadatos especificando esta vez TODOS los campos campos y 2) invocar al motor para que genere los gráficos.
Configuración de la tabla de metadatos¶
Además de los campos especificados para el servicio, será necesario especificar:
- table_name_division: nombre de la tabla que se publica por GeoServer con el nombre especificado en el campo
layer_name. - class_table_name: nombre de la tabla que tiene la clasificación forestal, con los polígonos de todos los años indicando la clasificación y la fecha en la fecha en la que es válido el polígono.
- class_field_name: nombre del campo en la tabla anterior que indica el tipo de clasificación para cada registro.
- date_field_name: nombre del campo que indica la fecha en la que el polígono es válido.
Invocación del motor para un gráfico determinado¶
El motor gráfico se invoca con la función redd_stats_run, que toma dos parámetros. El primero es el valor del campo id del registro de la tabla de metadatos cuyo gráfico queremos generar. El segundo es el esquema donde está esta tabla. La invocación se hace mediante una instrucción SELECT:
SELECT redd_stats_run(1, 'estadisticas');
Caso práctico¶
En este caso se parte de
- Una tabla
provinciascon un campoid_provinciacomo identificador. - Una capa en GeoServer, publicando la tabla anterior con el nombre
provinciasen el espacio de trabajobosques, es decir, con nombrebosques:provincias. - La tabla convenientemente publicada en el portal, de manera es es posible mostrar el diálogo de información al pinchar en una de las provincias.
- Una tabla
coberturacon los polígonos de la clasificación forestal y los campos:- un campo
clasificacindicando el tipo de la clasificación - un campo
fechaindicando el año de esa clasificación
- un campo
Es posible descargar los datos de ejemplo aquí, para su carga en PostGIS y la realización del caso práctico con ellos.
En este caso no creamos la tabla de datos, ya que ésta la creará el motor directamente, y pasamos directamente a añadir el registro en la tabla de metadatos:
INSERT INTO estadisticas.redd_stats_metadata (
title,
subtitle,
y_label,
units,
tooltipsdecimals,
layer_name,
table_name_division,
division_field_id,
class_table_name,
class_field_name,
date_field_name,
table_name_data,
graphic_type
) VALUES (
'Cobertura forestal',
'Evolución de la cobertura forestal por provincia',
'Cobertura',
'Hectáreas',
2,
'bosques:provincias',
'estadisticas.provincias',
'id_provinc',
'estadisticas.cobertura',
'clasificac',
'instante',
'estadisticas.cobertura_forestal_provincias_automatica',
'2D'
);
Puede verse cómo en este caso se han especificado los parámetros table_name_division, class_table_name, class_field_name, date_field_name, que permitirán al motor acceder a los datos y generar la tabla automáticamente.
Para invocar el motor basta con ver el id asignado al registro recién insertado:
spatialdata=> SELECT id, title, table_name_data FROM estadisticas.redd_stats_metadata;
id | title | table_name_data
----+--------------------+-------------------------------------------------------
5 | Cobertura forestal | estadisticas.cobertura_forestal_provincias_automatica
(1 row)
y ejecutar la función redd_stats_run() con el código que nos interesa y el nombre del esquema donde está la tabla redd_stats_metadata, es decir estadisticas:
SELECT redd_stats_run(1, 'estadisticas');
Tras la ejecución, la tabla estadisticas.cobertura_forestal_provincias_automatica estará rellena con el resultado de los cálculos:
patialdata=> select * from estadisticas.cobertura_forestal_provincias_automatica ;
division_id | variable | fecha | valor
-------------+-----------+------------+-------------
1 | bosque | 1999-01-01 | 6.37725e+07
1 | bosque | 2004-01-01 | 5.27672e+07
1 | bosque | 2010-01-01 | 8.30697e+07
1 | no bosque | 1999-01-01 | 1.8682e+07
1 | no bosque | 2004-01-01 | 2.97502e+07
1 | no bosque | 2010-01-01 | 0
2 | bosque | 1999-01-01 | 4.982e+07
2 | bosque | 2004-01-01 | 3.54705e+07
2 | bosque | 2010-01-01 | 0
2 | no bosque | 1999-01-01 | 4.55279e+07
2 | no bosque | 2004-01-01 | 5.98773e+07
2 | no bosque | 2010-01-01 | 9.53479e+07
3 | bosque | 1999-01-01 | 3.2107e+07
3 | bosque | 2004-01-01 | 2.52069e+07
3 | bosque | 2010-01-01 | 3.87162e+07
3 | no bosque | 1999-01-01 | 6.60003e+06
3 | no bosque | 2004-01-01 | 1.35093e+07
3 | no bosque | 2010-01-01 | 0
(18 rows)